







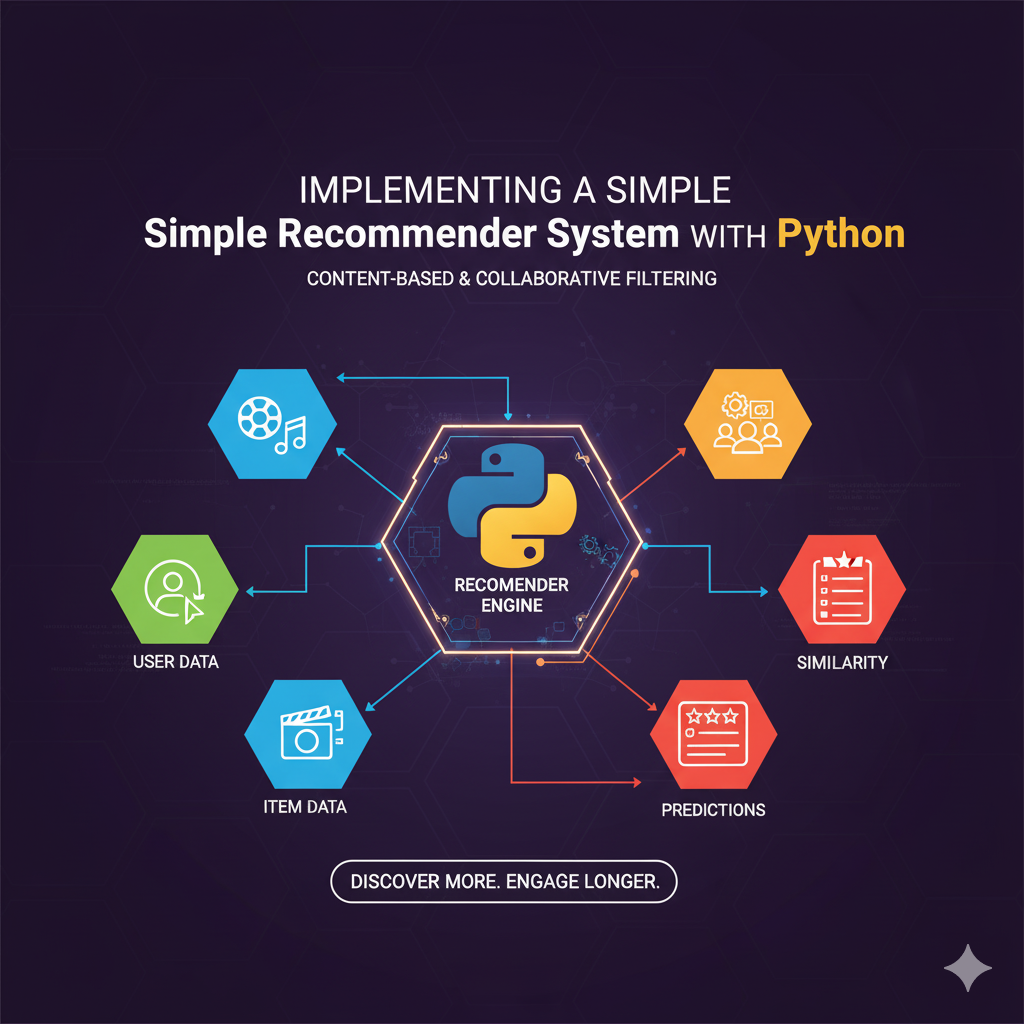
پیادهسازی سیستم پیشنهادگر ساده (Recommender System) با پایتون 💡🎬
تا به حال فکر کردهاید که چگونه نتفلیکس دقیقاً میداند شما چه فیلمی را دوست خواهید داشت، یا آمازون چگونه محصولاتی را پیشنهاد میدهد که انگار ذهن شما را خوانده است؟ جادوی پشت این سیستمها، سیستمهای پیشنهادگر (Recommender Systems) نام دارد. این سیستمها الگوریتمهایی هستند که بر اساس رفتار گذشته شما یا شباهت آیتمها، سعی میکنند پیشبینی کنند شما به چه چیزی علاقهمند خواهید بود. ساخت این سیستمها زمانی حوزه تخصصی شرکتهای بزرگ بود، اما به لطف قدرت و سادگی پایتون (Python) و کتابخانههای علم داده آن، امروزه حتی توسعهدهندگان تازهکار نیز میتوانند مدلهای پیشنهادگر ساده اما موثری را پیادهسازی کنند.
انواع اصلی سیستمهای پیشنهادگر 🤔
به طور کلی، دو رویکرد اصلی برای ساخت سیستمهای پیشنهادگر وجود دارد:
- ۱. پالایش گروهی (Collaborative Filtering): این روش بر اساس رفتار جمعی کاربران عمل میکند. ایده اصلی این است: “کاربرانی که در گذشته سلیقه مشابه شما داشتهاند، به چه آیتمهای دیگری علاقهمند بودهاند؟” یا “آیتمهایی که شبیه آیتمهای مورد علاقه شما بودهاند، کدامند؟”. این روش به دادههای تعامل کاربر-آیتم (مانند امتیازدهی یا کلیک) نیاز دارد.
- ۲. پالایش محتوامحور (Content-Based Filtering): این روش بر اساس ویژگیهای خود آیتمها عمل میکند. ایده اصلی: “اگر شما فیلمهای علمی-تخیلی با کارگردان کریستوفر نولان را دوست داشتهاید، احتمالاً فیلمهای دیگری با همین ژانر یا کارگردان را نیز دوست خواهید داشت.” این روش به اطلاعات توصیفی درباره آیتمها (مانند ژانر فیلم، توضیحات محصول) نیاز دارد.
- ۳. روشهای ترکیبی (Hybrid): این روشها از ترکیب دو رویکرد بالا برای غلبه بر محدودیتهای هر کدام استفاده میکنند.
در این مقاله، ما بر روی پیادهسازی یک سیستم پیشنهادگر ساده از نوع محتوامحور تمرکز خواهیم کرد که نقطه شروع خوبی برای یادگیری است.
جعبه ابزار پایتون: Pandas و Scikit-learn 🛠️
برای ساخت سیستم پیشنهادگر محتوامحور، به دو کتابخانه کلیدی پایتون نیاز داریم:
• Pandas:** برای خواندن، تمیز کردن و دستکاری دادههای جدولی (مثلاً لیست فیلمها و ویژگیهایشان).
• Scikit-learn:** یکی از قدرتمندترین کتابخانههای یادگیری ماشین در پایتون. ما از دو قابلیت اصلی آن استفاده خواهیم کرد:
- `TfidfVectorizer`: برای تبدیل متن (مانند خلاصه داستان یا ژانرهای فیلم) به بردارهای عددی قابل فهم برای ماشین.
- `cosine_similarity`: برای محاسبه شباهت بین این بردارهای عددی.
پروژه: ساخت پیشنهادگر فیلم بر اساس خلاصه داستان 🎬
فرض کنید یک مجموعه داده (مثلاً یک فایل CSV) از فیلمها داریم که شامل ستونهای `title` (عنوان) و `overview` (خلاصه داستان) است. هدف ما این است که کاربر نام یک فیلم را وارد کند و سیستم ۵ فیلم دیگر با خلاصه داستان مشابه را به او پیشنهاد دهد.
گامهای پیادهسازی (مفهومی):
- بارگذاری و آمادهسازی داده: خواندن فایل CSV با Pandas. بررسی مقادیر خالی (NaN) در ستون `overview` و پر کردن آنها با یک رشته خالی.
- تبدیل متن به بردار (Vectorization):
- ایجاد یک نمونه از `TfidfVectorizer`. TF-IDF روشی است که به کلمات مهمتر در یک متن وزن بیشتری میدهد.
- استفاده از متد `fit_transform` بر روی ستون `overview` برای ساخت یک ماتریس که در آن هر سطر نماینده یک فیلم و هر ستون نماینده یک کلمه (با وزن TF-IDF آن) است.
- محاسبه شباهت (Similarity Calculation):
- استفاده از `cosine_similarity` بر روی ماتریس TF-IDF. این تابع یک ماتریس مربعی ایجاد میکند که در آن هر سلول `[i, j]` نشاندهنده میزان شباهت (عددی بین ۰ و ۱) بین فیلم `i` و فیلم `j` است.
- ساخت تابع پیشنهادگر:
- تابعی بنویسید که عنوان فیلم مورد علاقه کاربر را به عنوان ورودی بگیرد.
- اندیس (index) این فیلم را در مجموعه داده پیدا کند.
- سطر مربوط به این فیلم را از ماتریس شباهت استخراج کند (این سطر شامل امتیاز شباهت این فیلم با تمام فیلمهای دیگر است).
- این امتیازها را به همراه اندیس فیلمها مرتب کند (از بیشترین شباهت به کمترین).
- اندیسهای ۵ فیلم برتر (به جز خود فیلم ورودی) را استخراج کند.
- عناوین فیلمهای مربوط به این اندیسها را از مجموعه داده اصلی بازیابی کرده و برگرداند.
نمونه کد پایتون (بخش اصلی):
import pandas as pd
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import cosine_similarity
# --- فرض کنید df یک DataFrame پاندازی است که قبلاً بارگذاری شده ---
# df = pd.read_csv('movies.csv')
# df['overview'] = df['overview'].fillna('') # Handle missing overviews
# 1. Vectorization
tfidf = TfidfVectorizer(stop_words='english') # stop_words remove common words like 'the', 'is'
tfidf_matrix = tfidf.fit_transform(df['overview'])
# 2. Similarity Calculation
cosine_sim = cosine_similarity(tfidf_matrix, tfidf_matrix)
# 3. Recommendation Function (Simplified)
# Create a mapping from movie title to index for quick lookup
indices = pd.Series(df.index, index=df['title']).drop_duplicates()
def get_recommendations(title, cosine_sim=cosine_sim):
try:
idx = indices[title]
except KeyError:
return f"فیلم '{title}' یافت نشد."
# Get similarity scores for the input movie
sim_scores = list(enumerate(cosine_sim[idx]))
# Sort movies based on similarity (descending)
sim_scores = sorted(sim_scores, key=lambda x: x[1], reverse=True)
# Get scores of the 10 most similar movies (excluding the movie itself)
sim_scores = sim_scores[1:11]
# Get the movie indices
movie_indices = [i[0] for i in sim_scores]
# Return the titles of the top 10 movies
return df['title'].iloc[movie_indices]
# --- Example Usage ---
# movie_title = "The Dark Knight Rises"
# recommendations = get_recommendations(movie_title)
# print(f"پیشنهادها برای '{movie_title}':\n", recommendations)
محدودیتها و گامهای بعدی ➡️
سیستمهای محتوامحور ساده، محدودیتهایی دارند:
• محدودیت در تنوع: عمدتاً آیتمهایی بسیار شبیه به گذشته را پیشنهاد میدهند و کشف علایق جدید برای کاربر دشوار است.
• نیاز به ویژگیهای خوب: اگر توضیحات آیتمها ضعیف یا ناقص باشد، عملکرد سیستم ضعیف خواهد بود.
برای سیستمهای پیشرفتهتر، میتوانید به سراغ پالایش گروهی (با کتابخانههایی مانند `Surprise`) یا روشهای مبتنی بر یادگیری عمیق (Deep Learning) بروید که میتوانند الگوهای پیچیدهتری را در رفتار کاربر و ویژگیهای آیتم شناسایی کنند.
جمعبندی ✅
سیستمهای پیشنهادگر یکی از کاربردیترین و جذابترین حوزههای علم داده هستند. پایتون با کتابخانههای قدرتمندی مانند Pandas و Scikit-learn، ابزارهای لازم برای پیادهسازی این سیستمها را به شکلی کارآمد در اختیار شما قرار میدهد. ساخت یک پیشنهادگر فیلم ساده بر اساس محتوا، یک پروژه عالی برای درک مفاهیم کلیدی مانند برداریسازی متن و محاسبه شباهت است و اولین قدم شما برای ورود به دنیای ساخت سیستمهای هوشمندی است که نیازهای کاربر را پیشبینی میکنند. این مهارتها در دورههای پیشرفته آموزش پایتون در آموزشگاه البرز به صورت عملی آموزش داده میشوند.
سیستمهای هوشمند پیشنهادگر بسازید! 🧠
با یادگیری پایتون و ورود به دنیای علم داده، میتوانید الگوریتمهایی بسازید که علایق کاربران را درک کرده و محتوا یا محصولات مناسب را به آنها پیشنهاد دهند.
- ✅ آموزش پایتون و کتابخانههای علم داده (Pandas, Scikit-learn)
- ✅ پیادهسازی عملی سیستمهای پیشنهادگر ساده
- ✅ درک مفاهیم TF-IDF و Cosine Similarity
ثبتنام در دوره پایتون و علم داده